
Summer research project I participated in: ‘Supporting Social Data Research with NoSQL Databases: Comparison of HBase and Riak’
This summer, I was accepted into a NSF-funded (National Science Foundation), two-month research project at Indiana University in Bloomington. Sponsored by the School of Informatics & Computing (SOIC), the program is designed to expose undergraduate students majoring in STEM fields to research taking place at the graduate level, in the hopes that they will elect to continue their education past a BS level. These programs are also often called REUs (Research Experiences for Undergraduates) and are offered nationwide at various times throughout the year.
Seeing as how I’ve been interested in Big Data/Data Science for some time now, and have wanted to learn more about the field, being accepted to this program was a dream come true! I could only hope that it would deliver on everything it promised, which it definitely did. The program was designed to immerse students as much as possible in normal IU life—for two months, it was as if we were enrolled there. We lived in IU on-campus dorms, had IU student IDs, access to all facilities, and meal cards that we could use at the dining halls. The program coordinators also planned a great series of events designed to expose us to campus facilities, resources, and local attractions. We also were able to tour the IU Data Center, which houses Big Red II (one of the two fastest university-owned supercomputers in the US).
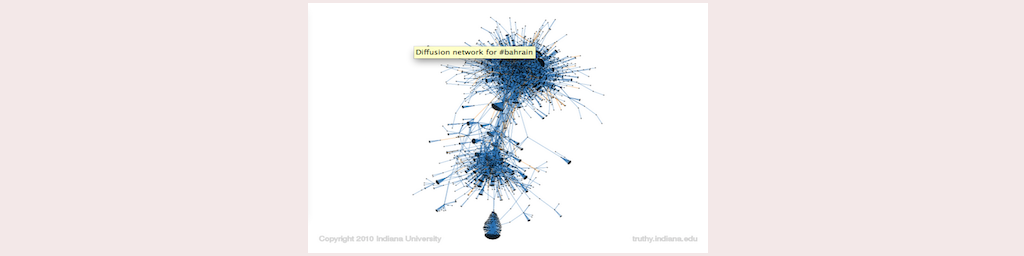
But on to the project! Entitled ”Supporting Social Data Research with NoSQL Databases: Comparison of HBase and Riak,” its aim was to compare the performance of two open-source, NoSQL databases: Apache’s Hadoop/HBase and Basho’s Riak platforms. We wished to compare them using a subset of the dataset of the Truthy Project—a project which gathered approximately 10% of all Twitter traffic (using the Twiiter Streaming API) over a two year period, in order to create a repository (i.e., gigantic data set) which social research scientists could conduct research with. Several interesting research papers have come out of the Truthy Project, such as papers investigating the flow and dissemination of information during Occupy Wall Street and the Arab Spring uprisings. In addition, the project researchers have also made very interesting images that portray information diffusion through users’ Twitter networks:
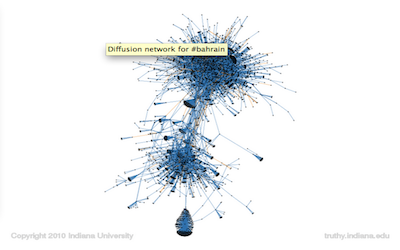
#bahrain.
Our project’s goal (link to project page) was to first set up and then configure both Hadoop/HBase and Riak, in keeping with the data set we were working with and the types of queries we’d be performing. I came in on the second half of the project—the first half, setting up and configuring Hadoop/HBase, and then loading data onto the nodes and running queries on it, had already been completed, so my portion dealt nearly exclusively with the Riak side of things. We had reserved eight nodes on IU’s FutureGrid cluster, a shared academic cloud computing resource that researchers can use for their projects. Our nodes were running CentOS (an enterprise Linux distro). Some of the configuration details included creating schemas for our data and managing the data-loading onto our nodes.
Next, we went on to perform some of the same search queries on our two databases that the Truthy Project researchers performed. These queries might be for a particular Twitter meme over various periods of times (a few hours, a day, five days, 10 days, etc.), the amount of posts a given user made over a certain period of time, or the number of user mentions a user received, just to name a few example queries. Due to the size of the data set (one month’s worth of tweets—350 GB), these queries might easily return results in the order of tens of thousands to hundreds of thousands of hits! As these are open-source platforms, there are a plethora of configuration options and possibilities, so part of our job was to optimize each platform to deliver the fastest results for the types of queries we were executing. For Riak, there are multiple ways to execute searches, some of which involved using MapReduce, so that added another layer of complexity—as we had to learn how Riak executed MapReduce jobs and then optimize for them accordingly.
Our results were very interesting, and seemed to highlight some of the differences between the two platforms (at least at the time of this project). We found Riak to be faster for queries returning < 100k results over shorter time periods, but Hadoop/HBase was faster for queries returning > 100k results over longer lengths of time. For Riak, some of this difference seemed to be attributed to how it handled returning results—they seemed to be gathered from all the nodes unsorted/ungrouped and streamed through just one reducer on one node exclusively, thus possibly creating the “bottlenecking” that resulted in result sets of a certain size. Hadoop/Hbase seemed to provide a more robust implementation of MapReduce, allowing for much more individual MapReduce node configuration and a design that seems to scale very well for large data sets.
Below is a graph which illustrates the results of one meme search conducted across different time ranges on both Riak and HBase (click for larger view):
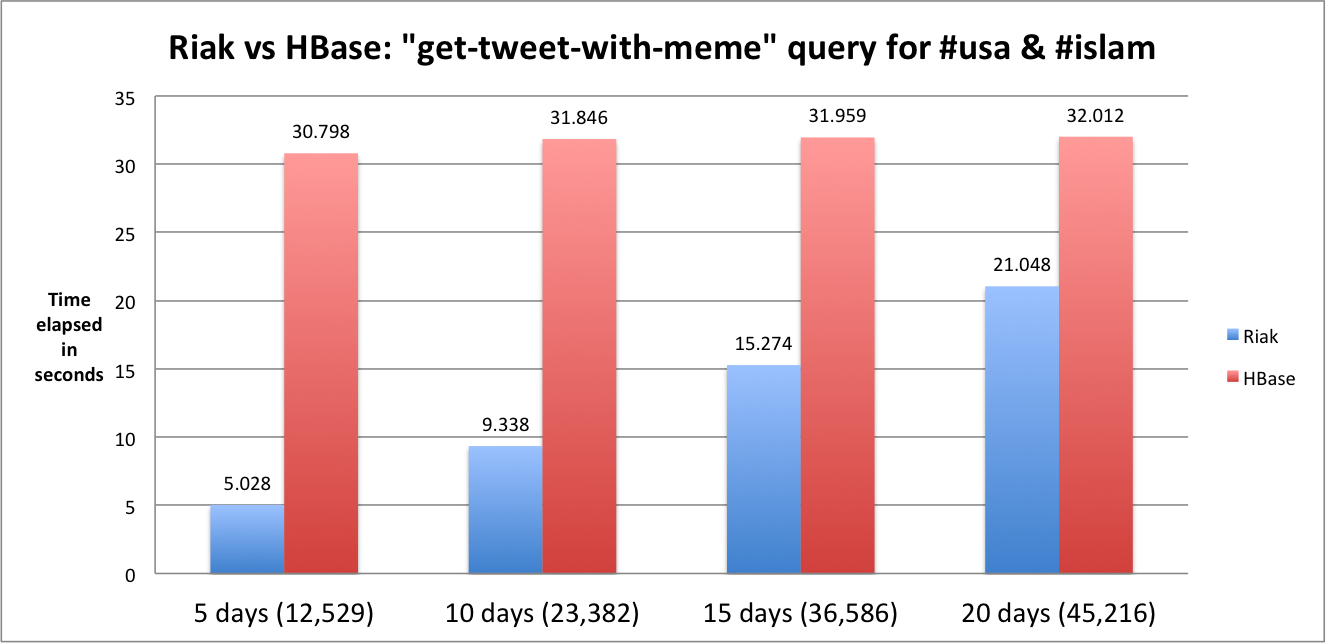
This histogram details the results for all tweets containing the meme “#ff” over periods of five, 10, 15, and 20 days. The number of results returned is next to each search period (for example, the search over five days for “#ff” on Riak returned 353,468 tweets in 126 seconds that contained that the search term). It is clear that, in this case, Riak is faster over a shorter period of time, but as both the search periods and result sizes increase, HBase scales to be far faster, exhibiting a much smaller, linear rate of growth than Riak. If anyone would like to view my research poster for this project, here is a link.
In conclusion, this was a wonderful experience and only served to whet my appetite for future learning. Just some of the languages, technologies, and skills I learned or were exposed to were: Python, Javascript, shell scripting, MapReduce, NoSQL databases, and cloud computing. I leave you with a shot of the beautiful campus:




Leave a comment